Announcing two 24k GPU clusters, Meta marks a significant investment in its AI future. Details on hardware, network, storage, design, performance, and software, crucial for high throughput and reliability in various AI workloads, are shared. These clusters, utilized for Llama 3 training, underscore Meta’s strong commitment to open compute and source, built atop platforms like Grand Teton, OpenRack, and PyTorch. This announcement signifies a step in Meta’s ambitious infrastructure roadmap, aiming to expand its GPU portfolio to include 350,000 NVIDIA H100 GPUs by 2024, equivalent to nearly 600,000 H100s’ computational power.

A peek into Meta’s large-scale AI clusters
Meta envisions a future where artificial general intelligence (AGI) is open and responsibly developed, benefiting everyone. Scaling clusters supports this goal, driving innovation in products, AI features, and computing devices. The AI Research SuperCluster (RSC), introduced in 2022 with 16,000 NVIDIA A100 GPUs, accelerates open and ethical AI research, advancing applications across various domains.
Beneath the Surface
The latest AI clusters build on past successes, emphasizing researcher and developer productivity. Equipped with 24,576 NVIDIA Tensor Core H100 GPUs each, these clusters support larger and more complex models than previous iterations, driving advancements in AI research and product development.
Network
Handling massive AI workloads demands sophisticated infrastructure. Custom-designed hardware, software, and network fabrics ensure optimal performance and efficiency. The clusters employ different network fabric solutions, allowing evaluation of their suitability for large-scale training without bottlenecks.
Compute
Built on the Grand Teton GPU platform, the clusters offer scalability and flexibility. Combined with the Open Rack architecture, they’re purpose-built for current and future AI applications.
Storage
Often overlooked but crucial, the storage solution meets the diverse needs of AI training. A distributed storage solution, complemented by Hammerspace, enhances developer experience and debugging capabilities.
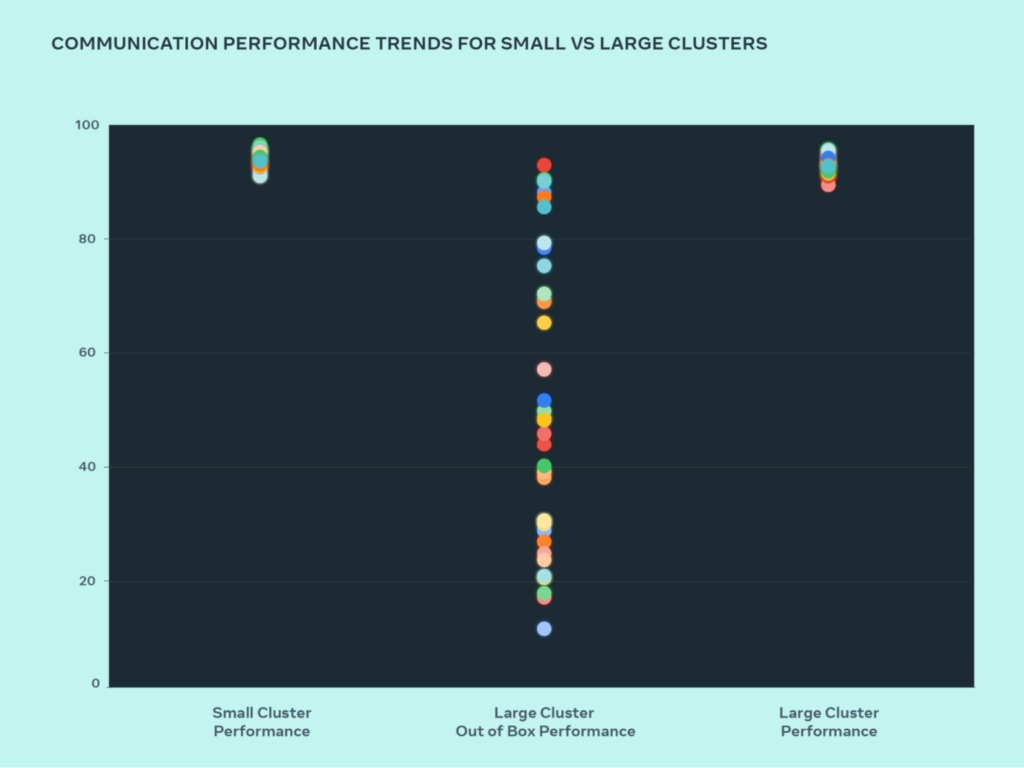
Performance
The focus is on maximizing performance and usability without compromise. Through testing and optimization, initial challenges have been overcome to achieve exceptional performance in large-scale AI clusters.
Link to the Article
https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/